728x90
반응형
본 포스팅은 제가 2013년 네이버 하둡스터디 카페에 포스팅했던 공개 강의 글입니다.
This is a public lecture that I posted on Naver Hadoop Study Cafe in 2013.
이번 세션에서는 하둡에 대해 본격적으로 공부하기 이전에 빅데이터에대해 알아보는 시간을 가지도록 하겠습니다.
하둡을 본격적으로 공부하기 전에 빅데이터를 알아야 하는 이유는.. 하둡 자체가 빅데이터를 저장하고 처리, 분석하기 위한 프레임 워크이기 때문입니다. 이에 빅데이터를 이해하셔야지만 하둡을 도입하고 구축하고 운영하실 수 있습니다.
이번 세션 이전에 Cloud Computing 공개 강의 게시판에 포스팅한 Cloud Computing 공개 강의 자료를 꼭 읽어보시기 바랍니다. 하둡, 빅데이터는 클라우드의 한 부분 이기 때문입니다.
자 이제 빅데이터에 대해 공개 강의를 포스팅 하겠습니다.
빅데이터란 무엇인가??
빅데이터 또한 클라우드 컴퓨팅과 같이 다양한 정의가 있습니다. 대부분 비슷비슷하지만 다양한 관점에서의 정의가 있어 하나의 문장으로 정의하기가 어려운 점이 있습니다. 이에 대표적인 빅데이터의 정의를 몇가지 소개해 드리도록 하겠습니다.
세계에서 가장 큰 인터넷 사전인 Wikipedia에서는 빅데이터를 "기존 데이터베이스 관리도구의 데이터 수집, 저장, 관리, 분석의 역량을 넘어서는 대량의 정형 또는 비정형 데이터의 집합이며, 이러한 데이터로부터 가치를 추출하고 결과를 분석하는 기술"을 빅데이터 (or 빅데이터 기술) 라고 정의하였습니다. 여기서 기존 데이텉베이스 관리도구는 RDBMS를 이야기합니다.
2011년 Mckinsey에서는 데이터베이스 관점에서 "일반적인 데이터베이스 S/W(RDMS)가 저장, 관리, 분석할 수 있는 범위를 초과하는 규모의 데이터"라고 빅데이터를 정의하였으며, IDC에서는 업무 수행관점에서 "다양한 종류의 대규모 데이터로부터 저렴한 비용으로 가치를 추출하고 초고속 수집, 저장, 발굴, 분석을 지원하도록 고안된 차세대 기술 및 아키텍쳐"라고 빅데이터를 정의하였습니다.
위에서 정의한 빅데이터는 빅데이터를 바라보는 차원에서의 정의가 있을뿐 정량적인 차원에서의 정의는 없습니다. 실제로도 그렇습니다. 굳이 빅데이터를 절대적인 크기로 정의한다면.. 주로 컨설팅 업체들에서는 (대표적으로 엑센츄어) 약 20TByte 이상의 데이터를 빅데이터로 분류한다고 합니다.
빅데이터 정의에 대해서 정리해 본다면 "서버 한대로 처리할 수 없는 규모의 데이터", "기존의 소프트웨어로는 처리할 수 없는 규모의 데이터", 뒤에서 차츰 설명 드리겠지만 "Scale-up 보다는 Scale-out을 지향", "3V(Volume, Velocity, Variety) 중 2V를 만족하는 데이터" 정도가 될 것 같습니다.
여기서 이야기하는 "Scale-up 보다는 Scale-out을 지향"의 의미는 하둡에서 지향하는 것인데요.. X86 급의 저사양 서버에서 데이터를 처리하고 데이터를 처리하기 위한 사양이 부족하다면 장비의 사양을 고사양으로 높이는 것(Scale-up)이 아니라 Memory 또는 저장장치, Server의 대수를 늘리는 것(Scale-out)입니다. 이유는 고사양의 장비를 추가 또는 교체하는 것보다는 x86급의 저사양 서버 여러대를 두어 처리하는 것이 금액적인 부분이나 성능적인 부분에서 더욱 효율적이기 때문입니다.
3V는 빅데이터를 특징을 이야기 하는 것인데요.. 흔히 3V중 2V를 만족할 경우 빅데이터라고 이야기 하고 있습니다.
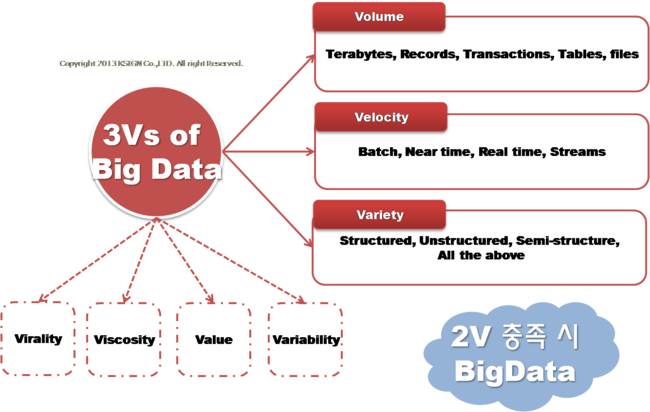
[그림 1] 빅데이터의 3요소
3V는 Volume(데이터의 크기), Variety(다양성), Velocity(데이터의 처리 속도) 이렇게 3가지 특성을 이야기 합니다.
그렇다면 이번에는 3V를 이용하여 빅데이터에 대해 설명해보도록 하겠습니다.
첫 번재로 Volume, 즉 데이터의 크기로 빅데이터를 설명하는 것인데요.. 일반적으로 수십 테라바이트 혹은 수십 페타바이트 크기 이상의 데이터가 빅데이터 범위에 해당한다는 것입니다. 이 특징을 가지는 데이터는 확장 가능한 방식(Scale-out)으로 데이터를 저장하고 분석하는 분산 컴퓨팅 기법으로 접근이 필요하며, 대표적인 분산 컴퓨팅 솔루션으로는 구글의 GFS(Google File System), 아파치 하둡의 HDFS(Hadoop Distributed File System) 이 있습니다.
두 번째로 Variety, 데이터의 다양성을 이야기하는 것입니다. 빅데이터는 정형(Structured), 반정형(Semi-Structured), 비정형(Unstructured) 데이터 모두를 처리할 수 있어야 합니다.
반응형
세번째로 Velocity는 데이터의 처리속도를 이야기하는 것인데요.. 실시간 처리를 해야하는 데이터와 장기적으로 접근해야하는 데이터를 이야기 합니다. 최근의 데이터는 빠른 속도로 생성되어 데이터의 생산, 저장, 유통, 수집, 분석이 실시간으로 처리되어야 합니다. 또한 수집된 대량의 데이터를 다양한 분석 기법과 표현기술로 분석하는 것은 장기적이고 전략적인 차원에서의 접근이 필요하다는 것을 의미합니다.
최근에는 Virality, Viscosity, Value, Variablitity 등의 단어를 추가하여 상황에 맞게 4V로 설명이 이루어 지기도 합니다.
Virality는 사전에서 찾아보면 소문이라는 뜻인데요, 이는 빅데이터에서 P2P 네트워크 등을 통해 사람들에게 분산되는 데이터 방식을 의미합니다. 즉 빠른 확산 속도를 가진다는 의미로 설명되고 있습니다.
Viscosity는 점성, 점도, 끈적거리는.. 이라는 뜻을 가지고 있습니다. 이를 빅데이터에서는 데이터 양에 대한 흐름, 데이터가 가지는 관계, 스트리밍, 통합적인 버스구조, 복잡한 이벤트 처리가 가능하다라는 것으로 설명을 하고 있습니다.
Variability는 데이터의 형태가 알려진 것인가? 급변하는 것인가? 등의 빅데이터의 특징을 이야기하는 것으로 3V중 Variety에서 파생된 특징이라고 생각하시면 됩니다.
지금까지 빅데이터의 정의와 특징에 대해서 살펴보았습니다. 그렇다면 이런 빅데이터라는 것이 왜 생겨 난 것일까요? 대체 왜 이런 데이터가 빅데이터라는 용어로 중요하게 여기어 지고 있는지 다음 세션에서 알아보도록 하겠습니다.
2023.12.19 - [hadoop study] - Cloud Computing Study Session #1-4 클라우드 컴퓨팅 (Cloud Computing) 서비스 및 구조
Cloud Computing Study Session #1-4 클라우드 컴퓨팅 (Cloud Computing) 서비스 및 구조
본 포스팅은 제가 2013년 네이버 하둡스터디 카페에 포스팅했던 공개 강의 글입니다. This is a public lecture that I posted on Naver Hadoop Study Cafe in 2013. * 본 세션 자료의 대부분 그림은 2013년 1월 숭실대학
takeanoteof.tistory.com
728x90
반응형
'hadoop study' 카테고리의 다른 글
| Hadoop Study Session #1-3 빅데이터 (BigData) 주요 기술 (1) | 2023.12.19 |
|---|---|
| Hadoop Study Session #1-2 빅데이터(BigData) 등장 배경과 중요성 (0) | 2023.12.19 |
| Cloud Computing Study Session #1-4 클라우드 컴퓨팅 (Cloud Computing) 서비스 및 구조 (0) | 2023.12.19 |
| Cloud Computing Study Session #1-3 클라우드 컴퓨팅 (Cloud Computing) 분류 (0) | 2023.12.19 |
| Cloud Computing Study Session #1-2 클라우드 컴퓨팅 (Cloud Computing) 개념 (0) | 2023.12.19 |




댓글