본 포스팅은 제가 2013년 네이버 하둡스터디 카페에 포스팅했던 공개 강의 글입니다.
This is a public lecture that I posted on Naver Hadoop Study Cafe in 2013.
* 본 세션 자료의 대부분의 내용 및 그림은 한빛교육센터에서 진행(4~5월)한 클라우드 빅 데이터 에코 시스템 과정 강의자료를 바탕으로 인용 및 제작되었음을 밝힙니다.
이번 세션에서는 먼저 빅데이터가 어떻게 분석되고 처리되는지에 대해 살펴보고 빅데이터의 주요 기술에 대해 살펴보도록 하겠습니다.
빅데이터의 처리 및 분석은 아래 [그림 1]과 같이 내부, 외부 데이터를 로그 수집기, 통합, 웹 로봇, RSS Feed, Open API등을 이용하여 수집하고, 배치처리 즉, Hadoop과 Gluster와 같은 분산 스토리지와 elasticsearch와 같은 검색툴, 실시간&배치가 가능한 NoSQl 또는 RDB를 이용하여 데이터를 저장합니다. 그리고 이렇게 저장된 빅데이터를 Hive와 Fig같은 스크립트 엔진 또는 하둡의 MapReduce, 분석알고리즘인 R과 같은 처리 분석 툴을 이용하여 빅 데이터를 분석하게 되며, 분석된 빅데이터를 DashBoard나 Graph와 같은 것으로 표현해줌으로써 빅데이터를 처리하고 분석하게 됩니다.

이러한 빅데이터를 분석하기 처리하기 위한 주요 기술은 아래 [그림 2]와 같이 표현기술, 분석 알고리즘 기술, 분석 인프라 기술, 관리도구 기술로 분류 할 수 있습니다.

위 [그림 2]에서 표현한 주요 기술을 다시 상세하게 스택으로 나타내보면 아래 [그림 3]과 같습니다. 크게 분석 인프라와 표현기술/알고리즘으로 분류할 수 있습니다. 실시간 분석과 데이터 처리 및 분석 기술은 표현기술/알고리즘과 분석 인프라 레벨에 모두 포함됩니다.

그렇다면 지금부터 위 [그림 3]에서 표현한 빅데이터 주요 기술 중 로그 수집 기술, 저장 기술(분산 스토리지), 저장 기술(NoSQL), 데이터 통합 기술, 데이터 분석 기술에 대해 알아보도록 하겠습니다.
빅데이터의 로그 수집 기술(도구)로는 빅데이터의 데이터(로그)수집 시스템의 요건은 수집 대상 서버 대수가 수천~수만대까지 무한 확장(Scale-out)이 가능한 확장성을 가지며, 데이터가 유실되지 않고 안전하게 저장되는 안정성, 수집된 데이터를 실시간으로 반영할 수 있어야하는 실시간성, 다양한 포맷의 정형/비정형 데이터를 지원해야하는 유연성을 만족해야합니다. 이러한 요건을 만족하는 빅데이터 로그 수집 기술(도구)로는 Cloudera에서 개발한 Flume, Yahoo에서 개발한 Chukwa, 페이스북에서 개발한 Scribe가 대표적입니다. 모두 현재 아파치 오픈 소프트웨어로 하둡의 서브프로젝트입니다.

현재 국내에서는 클라우데라의 Flume과 야후의 Chukwa가 많이 사용되고 있으며, 일본의 경우 페이스북에서 개발한 scribe도 많이 사용하고 있다고 합니다. 클라우데라같은 경우 하둡의 개발자인 더그커팅이 하둡 개발자들과 함께 차린 회사로 아파치 오픈프로젝트인 하둡의 유지 보수 및 개정을 주도 하고 있는 회사입니다. 때문에, 클라우데라에서 배포하는 하둡 프로젝트 기술이 많은 신뢰를 받고 전세계적으로 가장 많이 이용되고 있다는 점도 참고로 알아두시기 바랍니다.
두번째로 알아볼 빅데이터 주요 기술은 저장기술 중 분산스토리지 기술입니다. 빅데이터를 저장하기 위한 분산 스토리지는 범용 x86 서버와 SATA 디스크를 사용하여 저비용의 요건을 만족해야 하며, 수PB~수백PB 이상의 데이터를 저장할 수 있도록 고확장성을 가지며, 데이터 복제정책을 통한 데이터의 안정성을 보장하는 고가용, 대규모의 I/O처리가 이루어지며, Thoroughput의 선형 확장성을 위한 고성능 요건을 만족해야 합니다. 이렇게 4가지 정도의 요건을 만족하는 기술로는 Hadoop의 HDFS, OpenStack, GLUSTER, ceph 등이 있습니다.

세번째로는 빅데이터의 저장기술인 NoSQL에 대해 알아보도록 하겠습니다. NoSQL의 자세한 설명은 나중에 HBase 세션 전에 짚고 넘어가보도록 하고 이번 세션에서는 간단히 개념만 짚고 넘어가도록 하겠습니다.
빅데이터를 저장하는 대표적인 기술인 NoSQL은 비 관계형 데이터베이스를 지칭하는 데이터 저장소로 Not Only SQL로 표현하고 있습니다. NO SQL 등의 많은 표현이 있었지만 Not Only SQL로 굳혀져 가는 분위기 입니다. NoSQL은 모두 Key-Value 형식으로 데이터를 범용 서버에 분산하여 저장하는 것을 특징으로 가지고 있으며, 분산 병렬 처리에 적합한 확장성과 고성능 I/O를 제공하며, 데이터 스키마와 같은 속성들을 동적으로 정의한다는 특징을 가지고 있습니다. 하지만 기존 관계형 DB의 ACID 속성을 지원하지 않아 Join을 위해서는 별도로 프로그래밍 작업을 통해 구현해 주어야 한다는 단점을 가지고 있습니다.
대부분의 사람들이 NoSQL을 사용하면 기존 관계형DB를 대체할 수 있다고 생각하지만 절대로 관계형 DB의 대체 기술이 아니며, 서로 보완관계에 놓여 있음을 잊지 마셔야 합니다. 이유는 나중에 HBase세션 이전에 NoSQL세션에서 자세히 말씀 드리도록 하겠습니다.
NoSQL을 이야기 할때 반드시 접하게 되는 이론을 하나 소개해 드리겠습니다. 그 이론은 바로 CAP이론이라는 것인데요.. 많이 들어 보셨을 겁니다. CAP이론이란 Consistency(일관성), Partition Tolerance, Availability(신뢰성) 이렇게 세가지 속성을 모두 만족시키는 저장소는 구성하기 어려우며, 현존하는 데이터베이스는 CAP중 2가지를 만족한다 라는 이론입니다.
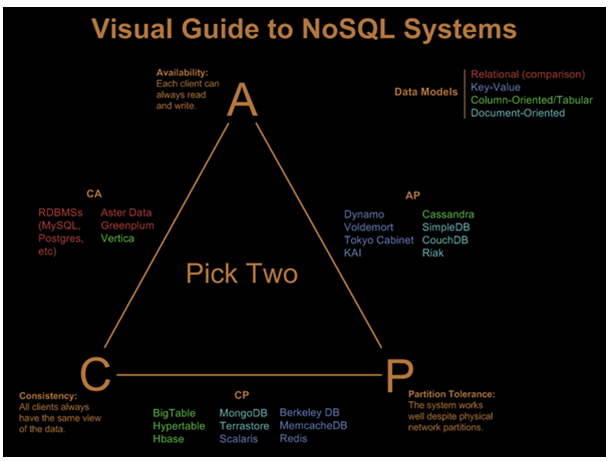
\Availability(신뢰성)이란 각 클라이언트에서 언제나 읽고 쓰기가 가능해야 한다라는 의미이며,
Consistency는 모든 클라이언트들이 언제나 같은 데이터를 조회했을때 같은 결과의 데이터를 얻을 수 있는 것을 의미합니다.
Partition Tolerance는 시스템의 파티션이 물리 네트워크로 분산되어 저장되어 하나의 시스템에 문제가 생겨도 시스템에 영향을 미치지 않는 다는 의미입니다. 어떻게 보면 Fault Tolerance와 비슷한 개념이기도 합니다.
Availability와 Consistency 특성을 만족하는 데이터베이스 시스템으로는 RDBMS에 속하는 MySQL, ORACLE과 같은 것 들이며, Consistency와 Partition Tolerance를 만족하는 데이터베이스 시스템으로는 대표적으로 MongoDB, HBase, BigTable, MemcacheDB 등이 있습니다.
마지막으로 Availability와 Partition Tolerance를 만족하는 데이터베이스 시스템으로는 Cassandra와 Dynamo 등이 대표적입니다.
지금까지 빅데이터의 주요 기술 중 로그 수집기술과 저장기술(분산 기술, NoSQL)에 대해 간단히 알아보았습니다. 계속하여 데이터 통합과 분석 기술에 대해서 알아보도록 하겠습니다.
네번째 빅데이터의 주요기술로 설명드릴 기술은 데이터 통합기술 입니다. 데이터 통합기술로는 기존 RDBMS와 하둡간의 데이터를 연결시켜주는 Sqoop이라는 기술과, WorkFlow기능을 제공하는 Oozie, Pantaho DI가 있씁니다. Oozie는 하둡에 특화된 WorkFlow OpenSource 이며, Pantaho DI는 오래전부터 사용되던 WorkFlow 프로그램으로 많은 기능을 포함하고 있다는 장점이 있습니다.
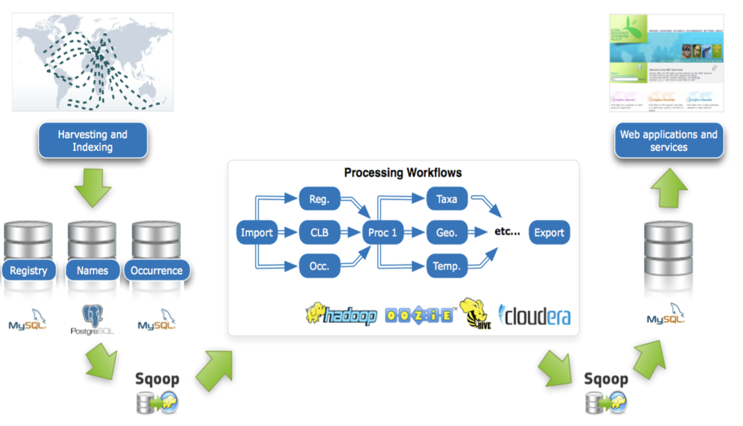
마지막 다섯번째로 알아볼 빅데이터의 주요 기술은 데이터 분석 기술입니다. 어떻게 보면 가장 중요한 기술 중 하나입니다. 어떠한 형태로 저장되어 있는 분석을 통해 결과를 얻어내야 하니까 말입니다. 데이터 분석기술로는 Google에 의해 고안된 병렬 푸로그래밍인 MapReduce와 오픈소스 Bulk Synchronous Parallel 모델인 Pregel(MapReduce 성능 보완), Query 문 형태로 MapReduce 작업 수행을 가능하게 해주는 Query엔진인 Hive와 Pig, GPU를 이용한 대량의 단순 연산 시 사용되는 GPGPU기술인 CUDA, 분석 알고리즘인 R, 기계학습을 우한 Apache의 Mahout이 있습니다.

각 오픈 소스의 설명은 두꺼운 책한권 분량이기 때문에, 이번 세션에서는 이런 것 들이 있다 정도로 소개하는 부분에서 마치도록 하겠습니다.
잠시 마지막으로 소개해 드리고 싶은 것이 있습니다.
..ㅠㅠ NoSQL에 대해 공부를 하고 있을 무렵... 구글검색에서 우연히 NewSQL이라는 녀석을 만났습니다..이제 겨우.. NoSQL을 공부하기 시작했는데.. RDB하고 NoSQL을 어떻게 잘 Job을 분배해서 데이터를 저장할 지 고민중에.. ㅠㅠ 벌써... 이제 막 공부시작했는데.. NoSQL... 하아... 푸념이 길어지는 군요.. 아.!! 2012년 09월 구글에서 SQL의 안전성과 NoSQL의 유연성을 살린 대용량 데이터 분산 처리 데이터 베이스 시스템인 NewSQL DB인 Spanner를 발표하였습니다. NoSQL 공부에만 너무 치중하지 마시고.. 새롭게 발표된 NewSQL에 대해서도..관심을 가져 주는 것이 좋을 것 같습니다... 분명.. 3~4년 안에는 이녀석이 무섭게 퍼질 것 같습니다. 지금의 하둡과 HBase마냥..ㅎ

NewSQL관련 자료 링크는 아래와 같습니다.
[Google에서 발표한 논문PDF 파일 : http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/ko//archive/spanner-osdi2012.pdf]
[번역 글: http://helloworld.naver.com/helloworld/216593]
지금까지 빅데이터 세션에서는 빅데이터에대해 간단히 소개해드리고 정의를 내려보았으며, 빅데이터의 등장 배경과 중요성에 대해서 살펴 보았습니다. 마지막 세션인 이번세션에서는 빅데이터의 처리 흐름과 주요 기술에 대해서 살펴봤습니다.
이번 세션을 마지막으로 빅데이터에 대해 공개 강의를 마치겠습니다. 부족한 공개 강의 포스팅이였지만 여러분들에게 많은 도움이 되었으면 합니다.
다음 세션부터 여러분들이 기다리고 또 기다리시던 하둡에 대해 본격적인 공개 강의가 진행되오니 많은 관심 부탁드립니다. ^^
2023.12.19 - [hadoop study] - Hadoop Study Session #1-2 빅데이터(BigData) 등장 배경과 중요성
Hadoop Study Session #1-2 빅데이터(BigData) 등장 배경과 중요성
본 포스팅은 제가 2013년 네이버 하둡스터디 카페에 포스팅했던 공개 강의 글입니다. This is a public lecture that I posted on Naver Hadoop Study Cafe in 2013. 이전시간에는 빅데이터의 개념과 특징을 살펴보았
takeanoteof.tistory.com
'hadoop study' 카테고리의 다른 글
| Hadoop Study Session #3-1 하둡 (Hadoop) 개요 (2) | 2023.12.24 |
|---|---|
| Hadoop Study Session #2 구글 시스템 소프트웨어 (Google System Software) (2) | 2023.12.22 |
| Hadoop Study Session #1-2 빅데이터(BigData) 등장 배경과 중요성 (0) | 2023.12.19 |
| Hadoop Study Session #1-1 빅데이터 (BigData) (0) | 2023.12.19 |
| Cloud Computing Study Session #1-4 클라우드 컴퓨팅 (Cloud Computing) 서비스 및 구조 (0) | 2023.12.19 |




댓글